TAB-Fields: A Maximum Entropy Framework for Mission-Aware Adversarial Planning
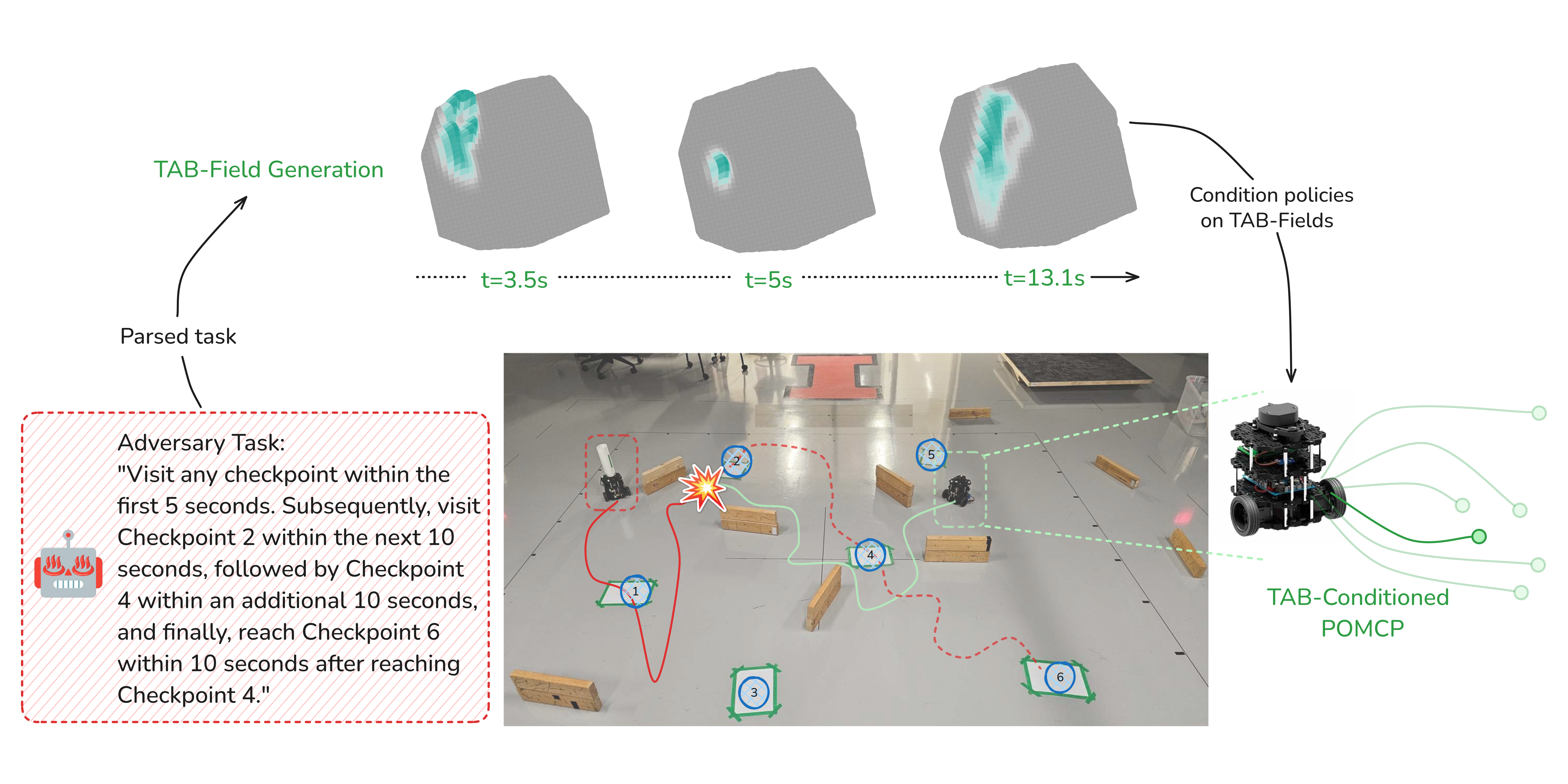
Autonomous agents increasingly operate in environments shared with other agents whose behavior affects mission success. How can we enable these agents to reason systematically about others' behaviors given only high-level information about their objectives? Can we develop approaches that avoid making unnecessary assumptions about others' decision-making processes while maintaining computational tractability?
Autonomous agents operating in adversarial scenarios face a fundamental challenge: while they may know their adversaries' high-level objectives, such as reaching specific destinations within time constraints, the exact policies these adversaries will employ remain unknown. Traditional approaches address this challenge by treating the adversary's state as a partially observable element, leading to a formulation as a Partially Observable Markov Decision Process (POMDP). However, the induced belief-space dynamics in a POMDP require knowledge of the system's transition dynamics, which, in this case, depend on the adversary's unknown policy. Hence, instead of assuming an adversary's policy, we propose characterizing the space of possible adversary behaviors through constraints derived from mission objectives and environmental factors. In this paper, we develop Task-Aware Behavior Fields (TAB-Fields), a representation that systematically captures adversary state distributions over time using principles of maximum entropy. By encoding only what is known—mission constraints and environmental limitations—TAB-Fields enable reasoning about the full range of feasible adversary behaviors without relying on policy assumptions or hand-crafted rewards. We integrate TAB-Fields with standard planning algorithms by introducing TAB-conditioned POMCP, an adaptation of Partially Observable Monte Carlo Planning. Through extensive experiments in simulation with underwater robots and hardware implementations with ground robots, we demonstrate that our approach achieves superior performance compared to baselines that either assume specific adversary policies or neglect mission constraints altogether.
Reach target [x,y] after visiting any three different checkpoints, taking no more than 10s between checkpoints, while avoiding the center of the environment.
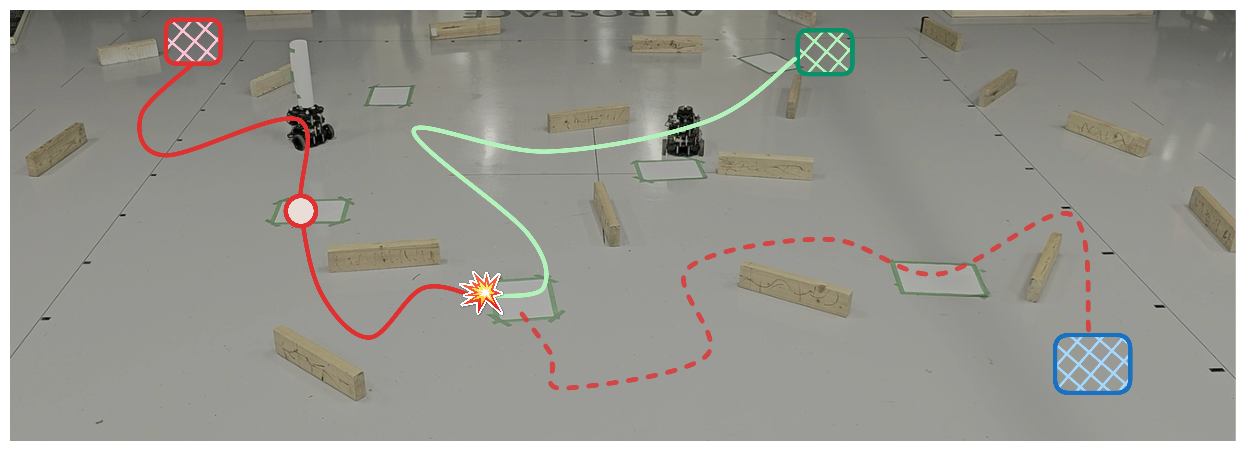
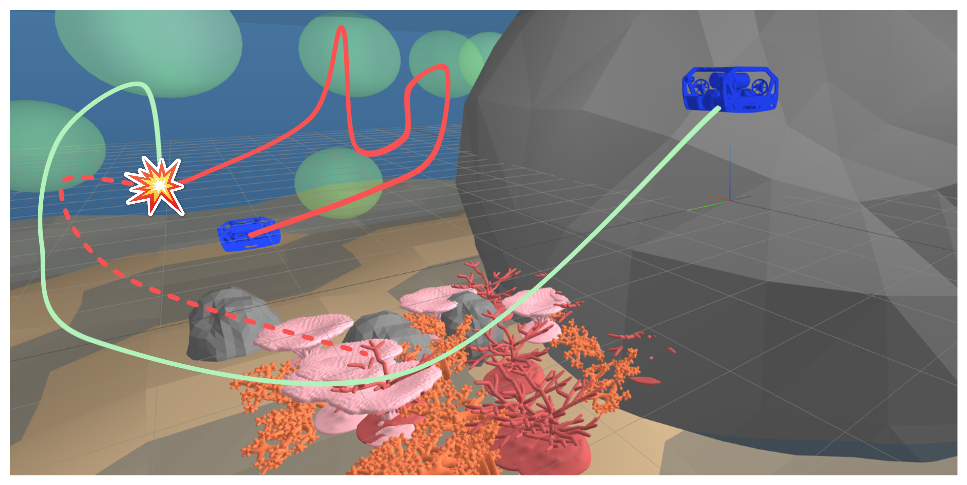
These videos demonstrate TAB-Field's performance in an "interception mission" of an adversary with various high-level objectives. In the videos, the adversarial agent is noted by a white hat and the checkpoints are depicted by green squares on the floor.
Start at the bottom-left corner, sequentially visit Checkpoint 3, Checkpoint 2, and Checkpoint 1 in that order, ensuring each checkpoint is reached within 7 seconds, and eventually finish at the top-right corner.
Start at the top-left corner, ensure you visit at least one checkpoint while always avoiding the center of the environment, and eventually reach the bottom-right corner within 50 seconds.
Start at the top-left corner, ensure you reach Checkpoint 1 exactly at 5 seconds, and eventually visit Checkpoint 2 within 10 seconds.
Start at the top-left corner, ensure that you are in a checkpoint every 10 seconds, and always avoid entering the right half of the environment.
Start at the top-right corner, ensure that exactly every 10 seconds you pass through a checkpoint, include Checkpoint 4 (the central checkpoint) as one of the three checkpoints, and eventually reach the bottom-right corner.
Start at the bottom-left corner, ensure that within 40 seconds you pass through the top-right corner and at least one other checkpoint, and eventually reach the center checkpoint within 80 seconds.
@article{puthumanaillam2024tabfieldsmaximumentropyframework,
title={TAB-Fields: A Maximum Entropy Framework for Mission-Aware Adversarial Planning},
author={Gokul Puthumanaillam and Jae Hyuk Song and Nurzhan Yesmagambet and Shinkyu Park and Melkior Ornik},
year={2024},
eprint={2412.02570},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2412.02570},
}
code>